Supported Technologies for Connecting Nodes in Data Pipeline Studio
While creating a data pipeline, you connect nodes of various stages to each other. The technologies that are supported in the stages depend on the capability you are using such as data integration, data transformation, data quality or data visualization. You must understand how the different stages of a data pipeline can be connected, depending on which technology you have added to the stage.
The following section lists the capabilities with the technology you choose and the supported combination of source and target nodes in Data Pipeline Studio.
This is what a typical data ingestion pipeline looks like in the Calibo Accelerate platform:

The Calibo Accelerate platform supports the following technologies for data integration stage in a data ingestion pipeline:
The following technologies are supported for source and target stages using Databricks for data integration:
| Source Stage | Data Integration Stage | Target Stage |
|---|---|---|
| CSV | Databricks | Amazon S3 |
| Databricks | Snowflake | |
| Databricks* | Azure Data Lake | |
| Databricks** | Unity Catalog Data Lake | |
| MS Excel | Databricks | Amazon S3 |
| Databricks | Snowflake | |
| Databricks* | Azure Data Lake | |
| Databricks** | Unity Catalog Data Lake | |
| Parquet | Databricks | Amazon S3 |
| Databricks | Snowflake | |
| Databricks* | Azure Data Lake | |
| Databricks** | Unity Catalog Data Lake | |
| FTP | Databricks (Templatized and Custom) | Amazon S3 |
| Databricks (Templatized and Custom) | Snowflake | |
| Databricks* (Templatized and Custom) | Azure Data Lake | |
| Databricks** (Templatized and Custom) | Unity Catalog Data Lake | |
| SFTP | Databricks (Templatized and Custom) | Amazon S3 |
| Databricks (Templatized and Custom) | Snowflake | |
| Databricks* (Templatized and Custom) | Azure Data Lake | |
| Databricks** (Templatized and Custom) | Unity Catalog Data Lake | |
| REST API | Databricks (Templatized and Custom) | Amazon S3 |
| Databricks (Templatized and Custom) | Snowflake | |
| Databricks* (Templatized and Custom) | Azure Data Lake | |
| Databricks** (Templatized and Custom) | Unity Catalog Data Lake | |
| Calibo Ingestion Catalog | Databricks | Amazon S3 |
| Databricks | Snowflake | |
| RDBMS - Microsoft SQL Server | Databricks (Templatized and Custom) | Amazon S3 |
| Databricks (Templatized and Custom) | Snowflake | |
| Databricks* (Templatized and Custom) | Azure Data Lake | |
| Databricks** (Templatized and Custom) | Unity Catalog Data Lake | |
| RDBMS - MySQL | Databricks (Templatized and Custom) | Amazon S3 |
| Databricks (Templatized and Custom) | Snowflake | |
| Databricks* (Templatized and Custom) | Azure Data Lake | |
| Databricks** (Templatized and Custom) | Unity Catalog Data Lake | |
| RDBMS - Oracle | Databricks (Templatized and Custom) | Amazon S3 |
| Databricks (Templatized and Custom) | Snowflake | |
| Databricks* (Templatized and Custom) | Azure Data Lake | |
| Databricks** (Templatized and Custom) | Unity Catalog Data Lake | |
| RDBMS - PostgreSQL | Databricks (Templatized and Custom) | Amazon S3 |
| Databricks (Templatized and Custom) | Snowflake | |
| Databricks* (Templatized and Custom) | Azure Data Lake | |
| Databricks** (Templatized and Custom) | Unity Catalog Data Lake | |
| RDBMS - Snowflake | Databricks (Templatized and Custom) | Amazon S3 |
| Databricks (Templatized and Custom) | Snowflake | |
| Databricks* (Templatized and Custom) | Azure Data Lake | |
| Databricks** (Templatized and Custom) | Unity Catalog Data Lake | |
| Amazon S3 | Databricks (Templatized and Custom) | Amazon S3 |
| Databricks (Templatized and Custom) | Snowflake | |
| Databricks** (Templatized and Custom) | Unity Catalog Data Lake | |
| Kinesis Streaming | Databricks | Amazon S3 |
| Databricks | Snowflake | |
| Azure Data Lake | Databricks* (Templatized and Custom) | Azure Data Lake |
| Azure Data Lake | Databricks* (Templatized and Custom) | Snowflake |
* Databricks instance must be deployed on Azure. For CSV, MS Excel, and Parquet data sources you must select a storage instance deployed on Azure.
** Databricks instance must be Unity Catalog-enabled. For CSV, MS Excel, and Parquet data sources you must select a Databricks instance enabled for Unity Catalog.
| Source Stage | Data Integration Stage | Target Stage |
|---|---|---|
| Salesforce | Amazon AppFlow | Amazon S3 |
| Amazon AppFlow | Snowflake | |
| ServiceNow | Amazon AppFlow | Amazon S3 |
| Source Stage | Data Integration Stage | Target Stage |
|---|---|---|
| Amazon S3 (Data Lake) | Snowflake Bulk Ingest | Snowflake |
| Source Stage | Data Integration Stage | Target Stage |
|---|---|---|
| Amazon S3 (Data Lake) | Snowflake Stream Ingest | Snowflake |
| Source Stage | Data Integration Stage | Target Stage |
|---|---|---|
| FTP/SFTP | Databricks (Unity Catalog-enabled) | Unity Catalog Data Lake |
| Data Ingestion Catalog | Databricks (Unity Catalog-enabled) | Unity Catalog Data Lake |
| Source Stage | Data Integration Stage | Target Stage |
|---|---|---|
| Amazon S3 (supported file formats - JSON, CSV, Parquet) | Databricks Autoloader | Unity Catalog Data Lake |
| Source Stage | Data Integration Stage | Target Stage |
|---|---|---|
| RDBMS - MySQL | Snowpark | Snowflake |
| RDBMS - PostgreSQL | Snowpark | Snowflake |
| RDBMS - Oracle | Snowpark | Snowflake |
Fivetran is used as a self-executing integration node.
Airbyte is used as a self-executing integration node.
This is what a typical data transformation pipeline looks like in the Calibo Accelerate platform:

The Calibo Accelerate platform provides data transformation using templatized jobs or custom jobs depending on the code that you use. Templatized jobs include join/union/aggregate functions that can be performed to group or combine data. For complex operations to be performed on data, DPS provides the option of creating custom transformation jobs.
The Calibo Accelerate platform supports data transformation using the following technologies:
| Source Stage | Data Transformation Stage | Target Stage |
|---|---|---|
| Snowflake | Databricks (custom transformation) | Snowflake |
| Amazon S3 | Databricks (templatized and custom transformation) | Amazon S3 |
| Azure Data Lake | Databricks (templatized and custom transformation) | Azure Data Lake |
| Source Stage | Data Transformation Stage | Target Stage |
|---|---|---|
| Snowflake | Snowflake (templatized and custom transformation) | Snowflake |
| Source Stage | Data Transformation Stage | Target Stage |
|---|---|---|
| Unity Catalog Data Lake | Databricks (Unity Catalog-enabled) | Unity Catalog Data Lake |
| Source Stage | Data Transformation Stage | Target Stage |
|---|---|---|
| Snowflake |
Snowpark (Python) (custom transformation) |
Snowflake |
| Snowflake |
Snowpark (Java - Gradle) (custom transformation) |
Snowflake |
| Snowflake |
Snowpark (Java - Maven) (custom transformation) |
Snowflake |
dbt is used as a self-executing node for data transformation.
This is what a typical data quality pipeline looks like in the Calibo Accelerate platform:
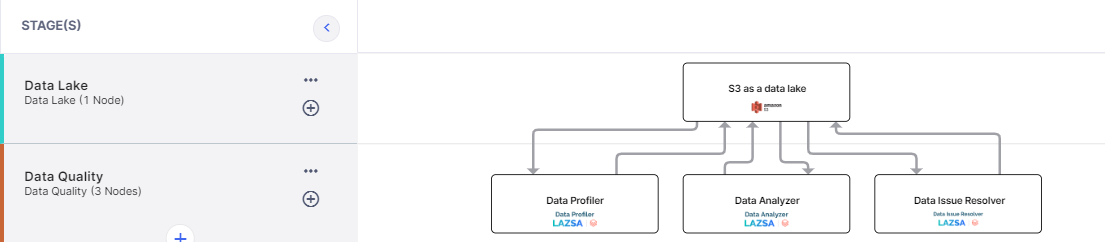
You can perform data quality using Databricks or Snowflake data quality capabilities, on the dataset available in an Amazon S3 data lake or a Snowflake data lake. The technology that you use entirely depends on the organizational preference.
The Calibo Accelerate platform provides various tools for data quality:
| Data Quality Stage | Target Stage |
|---|---|
| Data Profiler | Amazon S3 |
| Data Analyzer | Amazon S3 |
| Data Issue Resolver | Amazon S3 |
| Data Quality Stage | Target Stage |
|---|---|
| Data Profiler | Snowflake |
| Data analyzer | Snowflake |
| Data Issue Resolver | Snowflake |
| Data Quality Stage | Target Stage |
|---|---|
| Data Quality (DQ) Processor | Unity Catalog as data lake |
This is what a typical data visualization pipeline looks like in the Calibo Accelerate platform.

The following technologies are supported for data visualization:
This is what a typical data analytics pipeline looks like in the Calibo Accelerate platform.

The Calibo Accelerate platform provides the option of using either predefined algorithms like Random Forest Classifiers, Support Vector Classifier or creating custom algorithms according to your specific requirement.
| Source Stage | Data Analytics Stage | Target Stage |
|---|---|---|
| Snowflake | Python with JupyterLab | Snowflake |
| Amazon S3 | Python with JupyterLab | Snowflake |
| Snowflake | Python with JupyterLab | Amazon S3 |
| Amazon S3 | Python with JupyterLab | Amazon S3 |
| What's next? Create a Data Pipeline |